Grounded Object Referring
Grounded Object Referring is the task of locating objects in an image based on natural language descriptions—for example, "the man in a blue shirt" or "the dog sitting under the table." Unlike standard object detection, this task requires a deeper understanding of both visual details and linguistic nuances, including attributes, spatial relationships, and interactions.
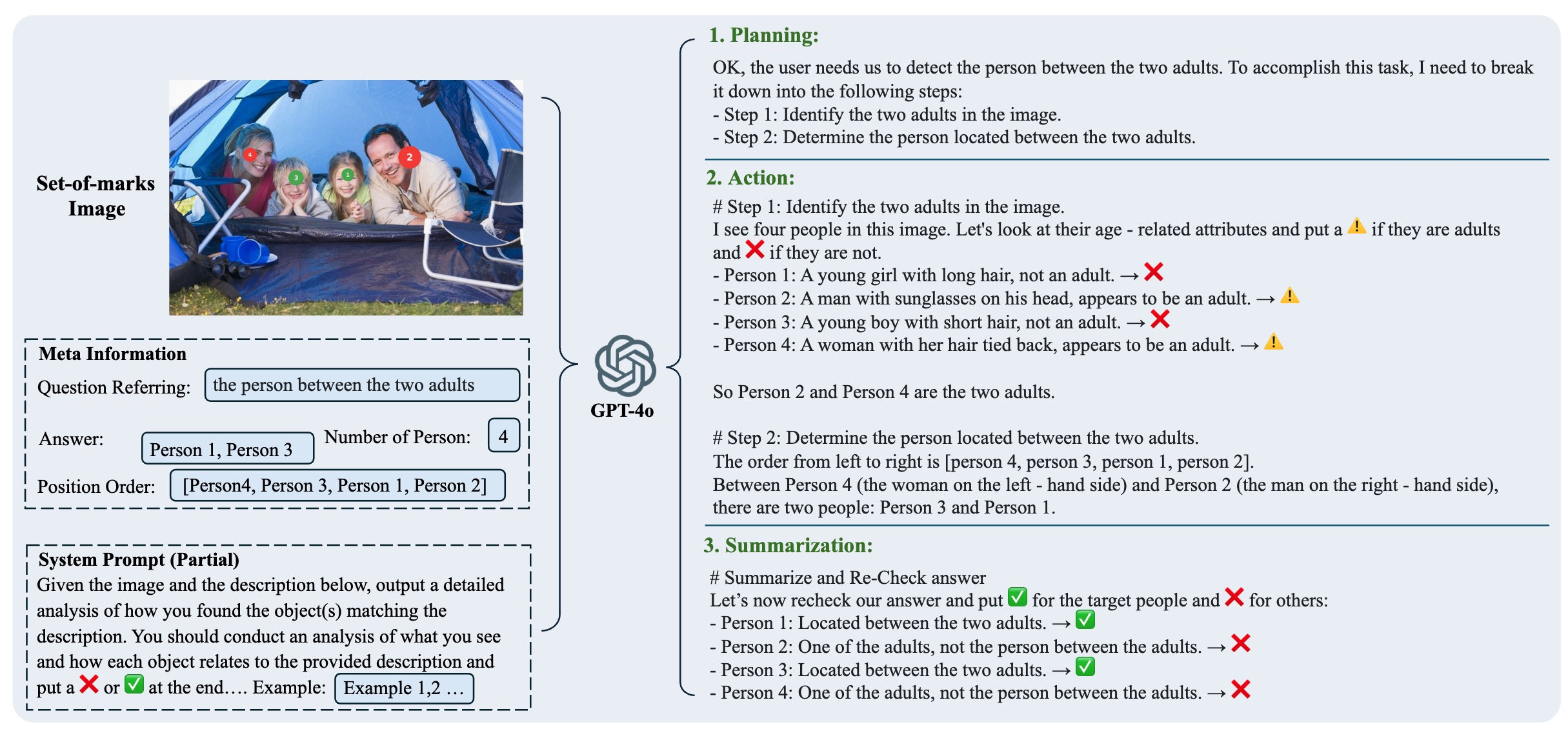
What makes it grounded is the focus on explainable and verifiable reasoning. Instead of guessing the object from the description, a grounded model reasons step-by-step—just like a human would. It first identifies possible candidates, then examines each one carefully based on the description, and finally selects the best match. This process reduces hallucination (predicting non-existent objects) and makes the model's decisions transparent and trustworthy.
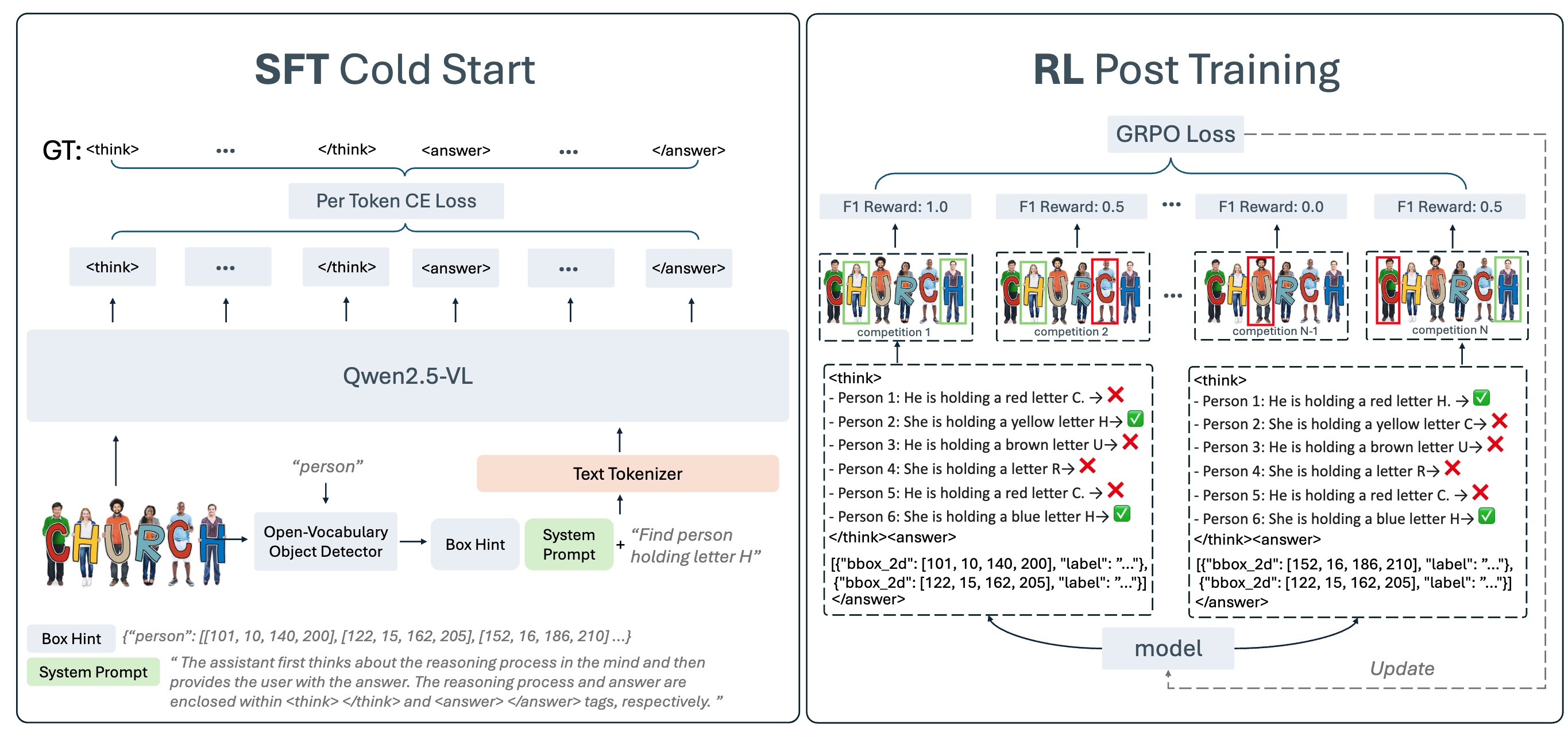
Our model, Rex-Thinker, tackles this task using Chain-of-Thought (CoT) reasoning, breaking down each decision into clear steps: Planning, Action, and Summarization. Combined with our HumanRef-CoT dataset and fine-tuning methods, this leads to state-of-the-art accuracy and interpretability.